
D'où est-ce que cette image vient ?
L’image en question a été générée grâce à un modèle d’IA open-source : Stable diffusion. En plus d’être open source, ce dernier, est sous licence Open RAIL ce qui autorise la réutilisation et la modification du modèle à des fins commerciales. C’est justement sur ce modèle que repose le site krea.ai (KREA - AI Creative Tool - image generations and prompts) qui propose de générer des images à partir d’un prompt, comme le fait midjourney ou DALL-E.
Jusque-là rien de bien nouveau car c’est depuis l’été 2022 que plusieurs sites sont apparus pour vous permettre de générer des images inédites à partir de prompts. De plus, en juin 2023 une ribambelle de QR générés avec stable diffusion avaient déjà déferlé sur la toile.

(hugging face)
La nouveauté ici est qu’en plus du prompt vous pouvez choisir un motif pour le faire ressortir dans votre nouvelle image fraichement générée. Cette nouvelle fonctionnalité proposée par Krea.ia s’appelle krea.ai/tool/patterns
Par exemple comment générer « Hello » en plein milieu d’un magnifique paysage grecque :
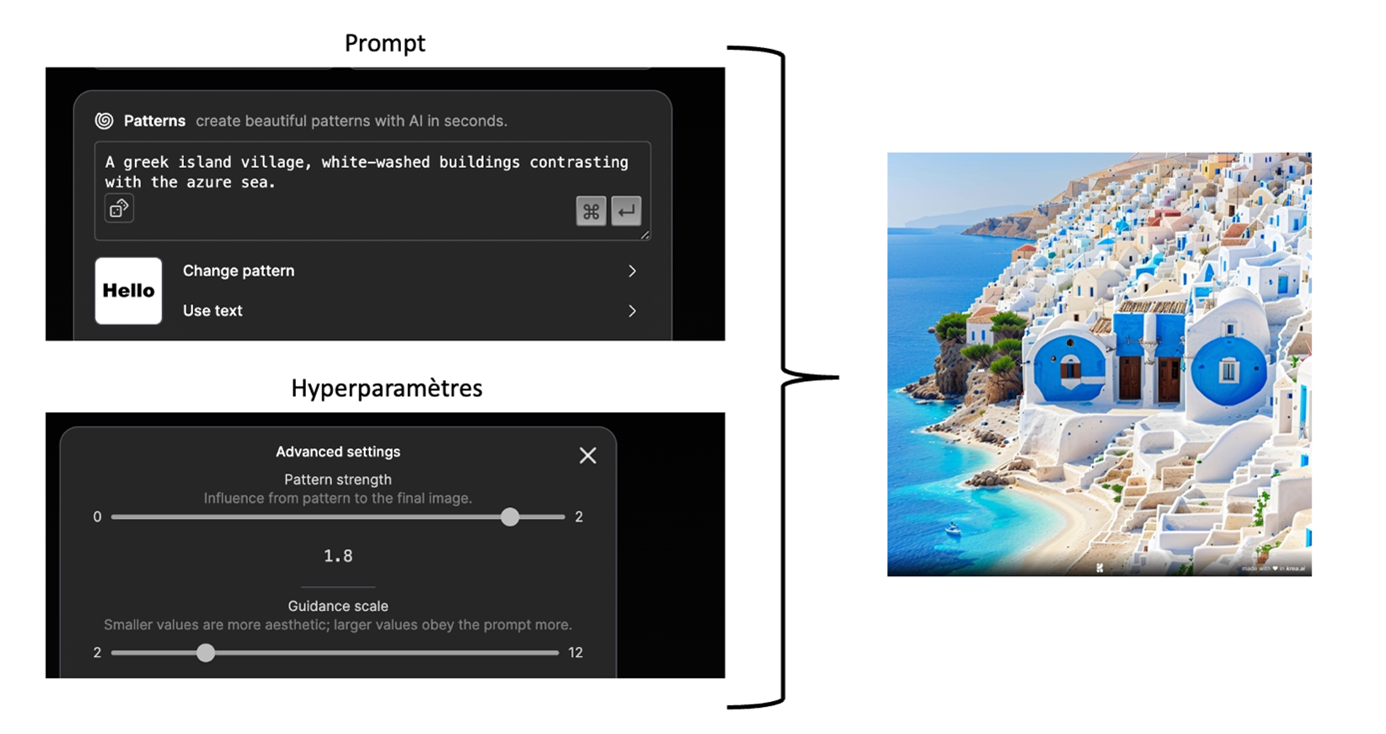
Comme souvent avec ces outils génératifs il faut quelques essais avant d’obtenir un résultat satisfaisant, dans cet exemple il y a deux éléments sur lesquels jouer. Le premier élément est prompt qui définit le paysage ou l'environnement où l'on souhaite afficher notre texte. Le second élément à ajuster concerne les hyperparamètres. Ces derniers permettent de mettre en avant ou de minimiser le texte. Pour cette étape, il n'existe pas de règle stricte ; il est nécessaire d'expérimenter différentes valeurs jusqu'à obtenir un résultat satisfaisant.
Dans l’image précédente on voit distinctement le mot « Hello » mais si on zoome l’intégration des lettres sont plus « naturelles ». Cette prouesse est rendue possible grâce à Stable diffusion.

Comment fonctionne ce générateur d'image ?
Stable Diffusion est un modèle d’IA multimodale, c’est-à-dire que plusieurs sources de données (exemple : vidéo, image, son) sont traitées et combinées pour résoudre des problèmes complexes. Dans le cas de Stable Diffusion, à la fois des images et du texte sont exploités pour générer des images.
Ce modèle offre deux options distinctes pour son utilisation. La première option consiste à générer des images à partir de texte uniquement. Dans ce scénario, l’utilisateur fournit une entrée textuelle (appelée prompt), et le modèle génère une image en réponse à cette requête. La deuxième option est quelque peu différente, car elle se concentre sur la génération d’une version modifiée d’une image existante. Pour ce faire, l’utilisateur saisit un prompt et fournit une image à altérer.
Stable Diffusion n’est pas constitué d’un unique modèle mais se compose d’un ensemble de modèles complexes. Dans cet article, nous décomposons ce modèle en deux composantes principales, que nous explorerons tout au long de notre discussion :
Le modèle de compréhension d’un prompt (la requête de l’utilisateur) par un modèle d’IA.
Le modèle de génération d’images à partir du prompt, à travers le principe de diffusion de l’information.
En examinant ces composantes essentielles de Stable Diffusion, nous comprendrons mieux le fonctionnement de ce modèle et ses capacités impressionnantes de génération d’images.
La représentation d’une requête textuelle
Le but essentiel des réseaux de neurones dédiés à la représentation de texte est de convertir un contenu textuel en une forme numérique appropriée à l'analyse par des modèles d'intelligence artificielle. Cette transformation se réalise en transposant des tokens dans un espace vectoriel multidimensionnel. En simplifiant, on peut imaginer cet espace comme un lieu où chaque mot du texte se traduit en un point dans un espace à deux dimensions (cf. figure 1).
-
Figure 1 - Exemple de représentation de mots dans un espace vectoriel à deux dimensions
Dans cet espace, nous pouvons discerner des liens sémantiques entre les mots. Plus les mots sont proches, plus leurs significations sont similaires. Dans l'exemple, nous constatons que les termes « écologie », « environnement » et « durable » sont étroitement liés, tandis qu'ils sont nettement éloignés du mot « chaise ». Cela nous permet de visualiser des thèmes, comme le thème de l'environnement dans l'exemple donné. Ce mécanisme s'avère extrêmement puissant, car il permet de reconnaître diverses reformulations d’une même phrase (par exemple, via des synonymes) sont similaires. En conséquence, le prompt de l'utilisateur est représenté avec une grande précision en tenant compte de la sémantique des mots qui le composent.
Le modèle de représentation de texte de Stable Diffusion repose sur l'utilisation de CLIP [2], qui est un modèle issu de la famille GPT et développé par OpenAI, dans sa version actuelle. Ce modèle appartient à la célèbre famille des modèles Transformer [3], qui ont connu une grande popularité depuis leur introduction en 2017.
L'entraînement de CLIP revêt un intérêt particulier, car il vise à associer du texte et des images pour évaluer leur similarité. Le modèle est entraîné avec des paires composées d’images et de légendes, qu’elles soient ou non associées à l’image en question. La figure 2 présente un exemple d’entraînement de ce modèle.

Figure 2 - Exemple d'entraînement du modèle CLIP
Dans sa nouvelle version 2.0, le modèle de Stable Diffusion présente des modèles robustes qui ont été appris en utilisant une nouvelle technologie de conversion texte en image appelée OpenCLIP. Cette avancée, développée par LAION avec le soutien de Stability AI, a considérablement amélioré la qualité des images générées par rapport aux versions précédentes.
Le mécanisme de diffusion
Les modèles de diffusion sont décisifs pour comprendre le fonctionnement de Stable Diffusion. L’idée est simple, à partir d’une image bruitée, nous souhaitons ajouter des informations de plus en plus nombreuses pour représenter une image finale.
Le principe de diffusion pour la génération d’images repose sur l’utilisation de modèles de vision par ordinateur puissants. De nos jours, avec un ensemble de données suffisamment grand, ces modèles parviennent à apprendre à réaliser des tâches complexes. Les modèles de diffusion abordent la génération d’images de la manière suivante :
Imaginez que nous ayons une image de départ. Nous générons un peu de bruit et l’ajoutons à cette image. Cette nouvelle image est différente de l’image de départ, et peut donc être ajoutée à l’ensemble d’entraînement. Nous répétons cette opération de nombreuses fois, avec des niveaux de bruits différents, pour créer de nombreux exemples d’entraînement afin de former la composante principale de notre modèle d’entraînement. Avec cet ensemble de données, nous pouvons apprendre un modèle de prédiction de bruit efficace qui est capable de générer des images lorsqu'il est exécuté dans une configuration spécifique.

Figure 3 - Exemple de génération d'images à partir de bruit [1]
La Figure 3 illustre que l'ajout de bruit à une image permet de créer de la diversité grâce à cette variation du bruit, ce qui conduit à la génération d'un tout nouvel ensemble d'images. Les auteurs de cette figure ont utilisé un modèle différent de celui exploité dans Stable Diffusion pour restaurer ces images à leur état initial, exempt de bruit. Cependant, le principe fondamental reste inchangé. L'augmentation de la quantité de bruit ajoutée à une image entraîne une diversification des images générées, et ce phénomène se produit à différentes intensités de bruit.
Le modèle UNet a été développé afin de prédire et de progressivement réduire le bruit présent dans une image. Ce modèle est très populaire car il est capable d’intégrer les données textuelles fournies par l’utilisateur à chaque étape du processus de débruitage. Grâce à cela, la réduction de bruit est guidée par la demande de l’utilisateur à chaque étape.
En résumé, la méthode de diffusion implique un processus graduel d'ajout de bruit à une image existante afin de générer des exemples d'entraînement. En se basant sur ces exemples, un modèle peut apprendre à produire des images de grande qualité en appliquant le bon type et la bonne quantité de bruit à une image donnée.
Conclusion
Le modèle Stable Diffusion est complexe car il combine plusieurs sources de données, à savoir des images et du texte. De plus, il intègre plusieurs modèles, ce qui lui permet d’atteindre de hautes performances dans la génération d’images à partir de texte (et à partir d’un ensemble de texte et d’image). De nombreux autres concepts sont impliqués dans la construction de ce modèle, mais nous pensons qu’ils sont plus simples à comprendre une fois que les mécanismes principaux ont été expliqués.
Quelles sont les perspectives ?
Les technologies d'Intelligence Artificielle générative transforment radicalement divers domaines d'activité et suscitent de nombreuses interrogations, notamment en ce qui concerne leur régulation juridique (Loi sur l'IA de l'UE : première réglementation de l'intelligence artificielle | Actualité | Parlement européen (europa.eu)).
Dans ce contexte, l'approche adoptée par Krea.ia grâce à « Stable Diffusion » se distingue particulièrement. Cette méthode présente un potentiel significatif pour dynamiser les stratégies de communication et de marketing. En effet, elle permet d'intégrer les logos des marques directement dans les images, offrant ainsi une opportunité d'amplifier et de personnaliser les messages adressés à la cible.
Toutefois, générer des visuels de haute qualité via ces technologies n'est pas une mince affaire. Elle requiert une maîtrise approfondie de divers éléments : le choix judicieux du modèle, la formulation précise du prompt, ainsi que l'ajustement optimal des hyper-paramètres.
Au-delà de ses applications dans les domaines artistique et marketing, cette technologie offre également des opportunités dans le secteur de la visualisation de données (ou dataviz). En utilisant l'IA générative, il est possible de concevoir des représentations graphiques de données plus impactantes, renforçant ainsi le message des informations présentées.

On espère que cette note vous aura permis de découvrir des choses sur la génération d'images, et sur les possibilités qu'offrent ces plateformes.
Rédacteurs :
- Alexandra BENAMAR - Docteur en Informatique
- Damien JACOB - Docteur en Physique Appliquée
Références :
[1] Xiao, Z., Kreis, K., & Vahdat, A. (2021). Tackling the generative learning trilemma with denoising diffusion gans. arXiv preprint arXiv:2112.07804.
[2] Radford, A., Kim, J. W., Hallacy, C., Ramesh, A., Goh, G., Agarwal, S., ... & Sutskever, I. (2021, July). Learning transferable visual models from natural language supervision. In International conference on machine learning (pp. 8748-8763). PMLR.
[3] Vaswani, A., Shazeer, N., Parmar, N., Uszkoreit, J., Jones, L., Gomez, A. N., ... & Polosukhin, I. (2017). Attention is all you need. Advances in neural information processing systems, 30.